Moving Beyond the ‚Dump and Pray‘ Approach: A Strategic Blueprint for Governance-Ready AI.

It’s the prevailing sales pitch of the moment: „Stop sorting files. Stop tagging documents. Just dump all your company data—PDFs, emails, Sharepoint, Slack logs—into our AI system. It will figure it out.“
If you have been in IT for more than a decade, this promise might trigger a sense of déjà vu. We have been here before. About ten years ago, the industry hyped the „Data Lake“. The promise then was identical: „Don’t worry about structure (Schema-on-Write), just dump it all in (Schema-on-Read).“
We all know how that ended. Most Data Lakes turned into Data Swamps—vast, unmanageable reservoirs of digital detritus where information went to die, irretrievable and lacking context.
Today, as we rush to implement RAG (Retrieval-Augmented Generation), we are not just repeating history; we are automating the creation of a much more complex problem. We are moving from the Data Swamp to the Vector Swamp.
The Mechanics of the „Vector Lake“
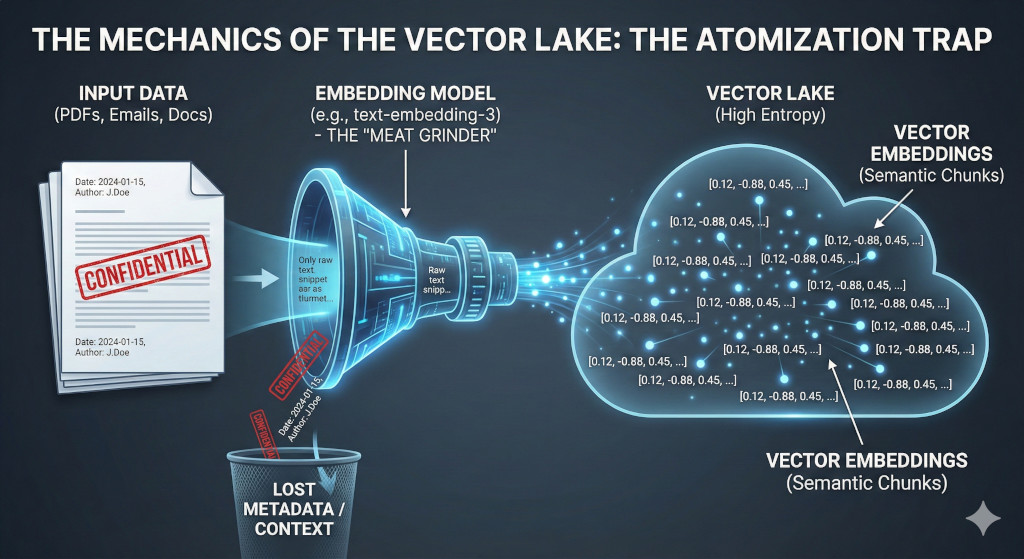
To understand the risk, we have to look under the hood of modern AI Search. Unlike traditional search engines that looked for keywords („Invoice 2024“), modern RAG systems use Embeddings.
The system takes your documents, shreds them into small pieces (called „chunks“), and sends them through an embedding model. This model translates text into a long string of numbers—a Vector. These vectors are coordinates in a multi-dimensional space representing semantic meaning. It feels like magic. You ask, „How do we handle refunds?“, and the system finds the relevant policy even if you didn’t use the exact word „refund.“
But here lies the trap. By relying solely on vectors, we introduce six governance-breaking flaws into our enterprise architecture.
1. The Architectural Flaw: Semantics Without Authority
In a traditional file system, a document has a context (Folder, Date, Author). In a Vector Lake, documents are atomized. A paragraph from a legally binding contract looks mathematically very similar to a paragraph from a casual email draft or a sarcastic Slack message.
Consider this scenario:
- Document A (Board Resolution): „We will acquire Company X.“
- Document B (Sarcastic Email): „I bet the CEO wants to acquire Company X just to get their coffee machine.“
To a vector database, these two are semantic neighbors. Without a normative framework, the AI retrieves both.
The Missing Link: Metadata The „Vector Swamp“ isn’t a law of nature; it is a result of lazy ingestion governance. A vector index without rigorous Metadata is an architectural failure. To build a functional system, we must filter before we search. We don’t just need to know what a document says, but what it is. Modern RAG systems must enforce filters like document_type = "policy" versus document_type = "draft", or status = "approved" versus status = "deprecated".
If you skip this structural metadata, you aren’t building a knowledge base; you are building a rumor mill.
2. The Dangerous Shift: From Search to Synthesis
We need to distinguish between two fundamentally different functions that vendors often conflate:
- AI-Assisted Search: „Show me the documents about Project X.“
- AI-Generated Answering: „Tell me the status of Project X.“
The risk explodes at step 2. A search engine that returns an outdated PDF is annoying. An AI that synthesizes a confident answer based on that outdated PDF is dangerous.
The Liability Question: This creates a massive organizational power shift. Who decides what is true? If the AI generates an answer based on three contradictory documents, it creates a „synthetic truth“ that no human ever authorized. In a corporate setting, truth is social and hierarchical, not just statistical. If we delegate the synthesis of truth to a probabilistic model, we create a liability vacuum.
3. The „Black Box“ of Operations: Where is the Audit Log?
For a governance-focused IT strategy, one piece is glaringly missing in most RAG setups: Observability.
Proponents argue that „Re-Rankers“ fix relevance issues. But this introduces non-determinism. In a SQL database, results are deterministic. In a Vector Store, they are probabilistic. If the AI hallucinates or provides a wrong answer, how do you debug it?
- Which specific chunks were retrieved?
- Why did the Re-Ranker prefer the email over the policy?
- Can you reproduce this answer tomorrow?
„The model thought it was relevant“ is not an audit statement that satisfies a regulator or a court. Operating a probabilistic system without rigorous Audit Logs and explainability tools is institutionally irresponsible.
4. The Data Hygiene Amplifier
AI does not fix bad data hygiene; it makes it visible—painfully so. Many companies suffer from „Zombie Knowledge“—policies that were never officially revoked but are practically dead. Pre-AI, these files gathered dust in deep subfolders. With AI, the semantic magnet pulls this zombie knowledge right to the surface.
If you have three versions of a guideline and no clear „Master Data Management,“ the AI will inevitably serve a cocktail of contradictions. RAG requires higher data quality than any previous technology.
5. The Legal Nightmare: Plain Text & GDPR
Beyond the structural issues, there is a legal minefield: GDPR and the problem of „Plain Text.“
For RAG to work, the AI must be able to read your data. It cannot process encrypted blobs; it needs plain text to generate answers. This creates a massive conflict with European data protection laws.
Consider the „Patient Scenario“: In 2015, a patient sends an email to their doctor describing a medical condition. This data was collected for a specific purpose: medical treatment. Ten years later, the clinic dumps its entire email archive into a cloud-based Vector Store.
- Purpose Violation: The patient never consented to have their sensitive health data (Art. 9 GDPR) processed by an AI for indexing.
- The „Cloud Act“ Risk: Even if the Vector Database is hosted in Frankfurt, if the provider is a US company (like Microsoft or OpenAI), they fall under the US Cloud Act. US authorities can theoretically demand access to that plain text data.
- The Right to be Forgotten: If the patient demands deletion in 2026, you are no longer looking for a file named „Müller.pdf“. You are looking for hundreds of anonymous, context-less vector chunks scattered across a database of millions. Finding and purging every snippet is a forensic nightmare.
6. The Economic Trap: The „Token Tax“
Finally, there is the bill. Moving from traditional search (fixed license cost) to Generative AI introduces a consumption-based pricing model that can spiral out of control.
The „Context Multiplier“: Imagine an employee asks a 5-word question. To answer it, the RAG system retrieves 10 pages of background documents and feeds them into the model. You are billed for processing thousands of words just to answer a simple query.
Furthermore, Vector Lock-in is real. Vectors are tied to the specific model that created them. If you want to switch from Provider A to Provider B next year, you cannot convert the data. You must re-process—and re-pay for—every single document. You are building your castle on rented land.
The Philosophical Root: The Entropy Illusion
Why do these problems persist? We can look to Information Theory (Claude Shannon) and Systems Theory (Niklas Luhmann) for the answer.
Luhmann defined systems by their ability to reduce complexity through distinction (e.g., distinguishing between „Draft“ and „Final“). When we dump data into a Vector Lake, we engage in de-differentiation. We strip away the boundaries that give data its meaning.
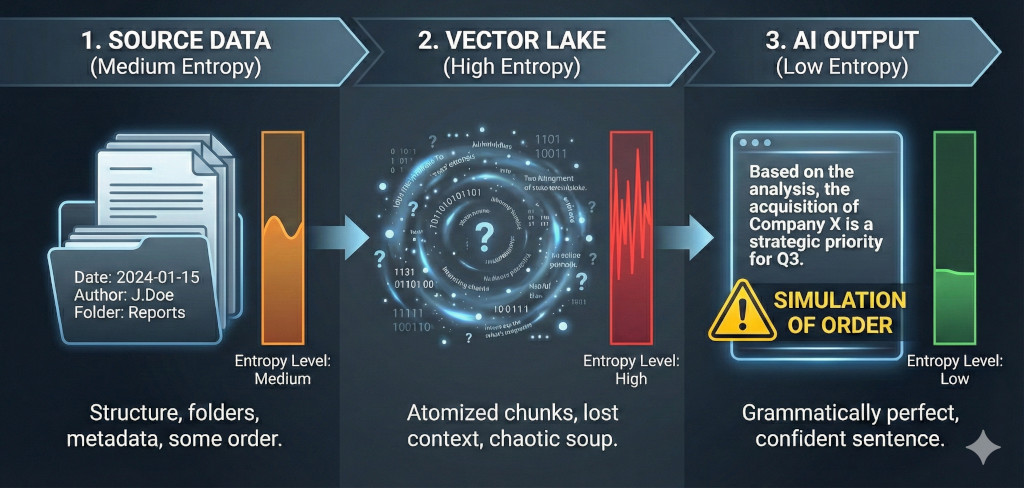
We are essentially running a dangerous cycle of Entropy:
- Source Data (Medium Entropy): Your files have structure, folders, and dates. They are somewhat ordered.
- Vector Lake (High Entropy): We pulverize these files into atomized chunks. Context is lost. The database becomes a chaotic soup of semantic snippets.
- AI Output (Low Entropy): The LLM takes this chaos and forces it into a grammatically perfect, confident sentence.
The Danger: The user sees the low-entropy output (the clean answer) and assumes it represents truth. In reality, it is often just a simulation of order generated from a state of chaos. Without metadata and structure, we are simply hallucinating logic where there is none.
The Blueprint: A Strategic Roadmap for Decision Makers
So, is RAG dead? No. But the „Dump & Pray“ approach is. To build a system that delivers value without creating a governance liability, we need to shift from a tech-first to a Strategy-First Architecture. Here is the roadmap:
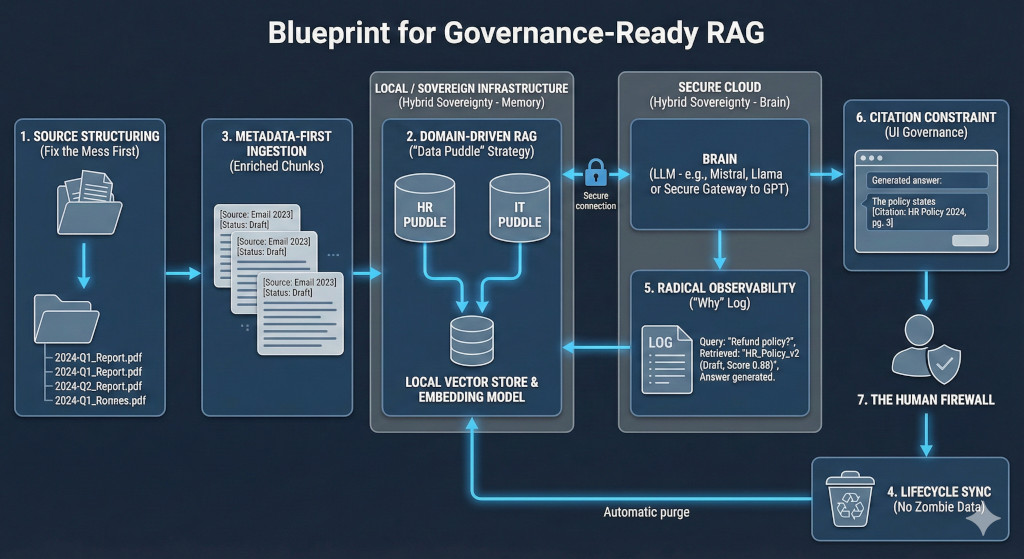
1. The Prerequisite: Cultural Readiness & Data Hygiene
Before you procure a Vector Database, look at your file server. AI is not a magic janitor that tidies up your folders; it is a mirror that reflects your existing chaos.
- The Strategy: You cannot solve this with software alone. You need a Data Literacy Initiative. Employees must be trained to store documents with standardized naming conventions and in correct locations before ingestion begins.
- The Benefit: Meaningful filenames and paths are the most valuable „free“ metadata you have. If your team fixes the source, the AI automatically understands context. If you skip this cultural step, you are investing in a „Garbage In, Garbage Out“ machine.
2. Domain-Driven RAG (The „Data Puddle“ Strategy)
Stop trying to build one monolithic Oracle that knows everything from the cafeteria menu to the CEO’s bonus targets.
- The Strategy: Segment your Vector Store into strictly separated Domains. Build one physical index for „HR Policies“ and a completely separate one for „IT Documentation.“
- The Benefit: This creates hard security barriers. An engineer asking about „Python“ will never accidentally retrieve a sensitive finance document, because the indices are physically disconnected.
3. Metadata-First Ingestion (Enriched Chunks)
Ingestion is not just a file upload; it is an ETL (Extract, Transform, Load) process.
- The Strategy: Demand „Metadata Injection“ from your vendors or architects. Context (Source, Date, Status) must be prepended to every text chunk before it is vectorized.
- The Benefit: This bakes the context directly into the vector. Even if the semantic search finds a keyword, a „Draft“ tag will push the document down in the ranking.
4. Hybrid Sovereignty (Decouple Memory from Reasoning)
This is the most critical architectural decision to avoid lock-in and privacy breaches.
- The Strategy: Separate the „Memory“ from the „Brain.“
- Memory: Host the Vector Store and Embedding Model locally or on sovereign infrastructure.
- Brain: Use local LLMs for sensitive internal queries. Only route non-critical, public-data queries to US-Cloud models.
- The Benefit: Your long-term corporate memory remains your property and stays compatible, even if you change the „Brain“ provider next year.
5. Radical Observability (The „Why“ Log)
You cannot manage what you cannot measure. „It works mostly“ is not an acceptable status for enterprise IT.
- The Strategy: Mandate Tracing for every single query. Logs must show the user prompt, the exact retrieved documents, and the relevance score.
- The Benefit: When a user claims the AI „lied,“ you have a forensic trail to see exactly which outdated document caused the hallucination.
6. The „Human Firewall“: Training & Usage Governance
Technology cannot fix a lack of discipline. The safest system will fail if users blindly trust it.
- The Strategy: Establish a clear policy: AI answers are drafts, not verdicts. Train staff to verify citations. The liability for a decision must explicitly remain with the human user, never the tool.
- The Benefit: This shifts the corporate mindset from „The AI said so“ to „The AI helped me find this.“
Conclusion
Structure, metadata, and data culture are not legacy burdens to be discarded. They are the prerequisites for AI. If we ignore this, we aren’t building an Oracle. We are just building a very expensive, eloquent generator of confusion.
Hermann Himmelbauer, Jänner 2026